
Designing a Scalable Real Time Stock Price Streaming System
Designing a Scalable Real Time Stock Price Streaming System
Real-time stock price streaming is one of the most challenging backend problems because it involves:
- High-frequency data ingestion (from exchange feeds)
- Continuous real-time delivery to thousands (or millions) of users
- Efficient time-series storage
- Infinite incoming data
- Low-latency push to web and mobile clients
- Cost-efficient long-term archival
In this article we’ll design a complete end-to-end system that can power a lightweight stock market app or even scale up to hedge-fund level infrastructure.
We will explore:
- WebSockets vs Server-Sent Events (SSE)
- Database choices & trade-offs
- Handling infinite streaming data
- Hot/Warm/Cold storage strategies
- A production-grade architecture design
- Horizontal scaling
- Full system diagrams (ASCII + Mermaid)
Let’s begin.
1. Real-Time Updates: WebSockets vs SSE
A stock app needs to push updates to users in real-time. There are two main communication options:
WebSockets
WebSockets are full-duplex, meaning the client and server can talk to each other at any time.
✅ Pros
- Very low latency
- Bidirectional
- Efficient for high-frequency streaming
- Supports binary formats (ProtoBuf/CBOR)
- Stable across mobile networks
❌ Cons
- Must implement heartbeats (ping/pong)
- Risk of zombie connections if not cleaned
- Requires sticky sessions when load-balanced
- Slightly more complex than SSE
Server-Sent Events (SSE)
SSE is unidirectional (server → client) using HTTP streaming.
✅ Pros
- Simpler than WebSockets
- Auto-reconnect built-in
- Uses HTTP—easy to debug
- Ideal for one-way updates
❌ Cons
- Client cannot push messages back
- Text-only (no binary)
- Can break often on mobile networks
- High-frequency streams (50+ msgs/sec) struggle
Which should we choose?
| Requirement | Winner |
|---|---|
| High-frequency updates | WebSockets |
| Unidirectional updates | SSE |
| Mobile stability | WebSockets |
| Simplicity | SSE |
| Bidirectional communication | WebSockets |
For a stock app → WebSockets are the strongest long-term choice.
But we will design the system to support either.
2. Ingesting Tick Data from Exchanges
Most stock exchanges publish data via:
- FIX feeds
- WebSocket streams
- Proprietary streaming protocols
- Kafka-based market data feeds
Your backend will subscribe to a real-time tick data stream like this:
AAPL → 190.45
TSLA → 241.12
MSFT → 329.01
These events come in continuously and infinitely.
3. Database Choices for Tick Data
Tick-level market data is extremely high volume:
- Thousands of ticks per second
- Millions of rows per day
- Billions of rows per year
Not all databases can store this.
Let’s compare options.
A. TimescaleDB (based on PostgreSQL)
Great for:
- Time-series queries
- SQL familiarity
- Retention policies
- Compression
Limitations:
- Horizontal scaling is manual
- Not ideal for >100K writes/sec
- Storage still fills unless you prune data
B. ClickHouse
Best columnar analytics database in the world.
Pros
- Writes millions of rows/sec
- Extremely compressed storage
- Built-in sharding & replication
- Perfect for large tick datasets
- Querying is blazing fast
Cons
- Horizontal scaling is not fully automatic
- Old data must be manually tiered or moved to S3
C. QuestDB
Insanely fast ingestion, optimized for time-series.
Cons
- No clustering
- Single-node only
- Not good for infinite long-term storage
D. Redis (not for history)
Redis is not your primary database.
Use Redis only to store:
- Current price of each symbol
- Last X seconds/minutes of data (cache)
It supports instant lookup for WebSocket updates.
E. Cassandra / ScyllaDB (infinite scale, limited analytics)
Cassandra provides:
- Automatic horizontal sharding
- Infinite storage scaling (via consistent hashing)
But:
- Not columnar
- Not ideal for analytical queries
- Expensive for ad-hoc history lookups
4. Why You Cannot Store Infinite Tick Data in Any DB
Here’s the truth:
No time series database can store infinite tick data forever, even with sharding.
There will always be:
- Disk limits
- Retention constraints
- Cluster rebalancing challenges
- Costs that grow linearly or exponentially
So real financial systems use data tiering.
5. Solving Infinite Data: Hot/Warm/Cold Storage
🔥 Hot Storage (real-time)
- Redis
- In-memory
- Last 50–100 ticks
- Millisecond latency
- Used by WebSocket/SSE servers
🌤️ Warm Storage (recent history)
- ClickHouse / TimescaleDB
- Keep 7 days – 30 days of raw ticks
- High compression
- Fast analytics
❄️ Cold Storage (long-term archival)
- S3
- Glacier Deep Archive
- Parquet/ORC files
- Extremely cheap
- Used for: compliance, ML models, historical charts
6. Data Lifecycle
- ✔ 1. Ticks enter Kafka
- ✔ 2. Processor writes ticks to ClickHouse (30 days retention)
- ✔ 3. Every N hours:
- compress old partitions
- dump old data to S3 as Parquet
- ✔ 4. Delete old partitions in DB
- ✔ 5. Update Redis with latest prices
- ✔ 6. WebSocket servers broadcast to clients
This is the architecture used by:
- Robinhood
- Binance
- Coinbase
- Bloomberg Terminal
7. Final System Architecture
Below is a complete end-to-end architecture.
Design Diagram
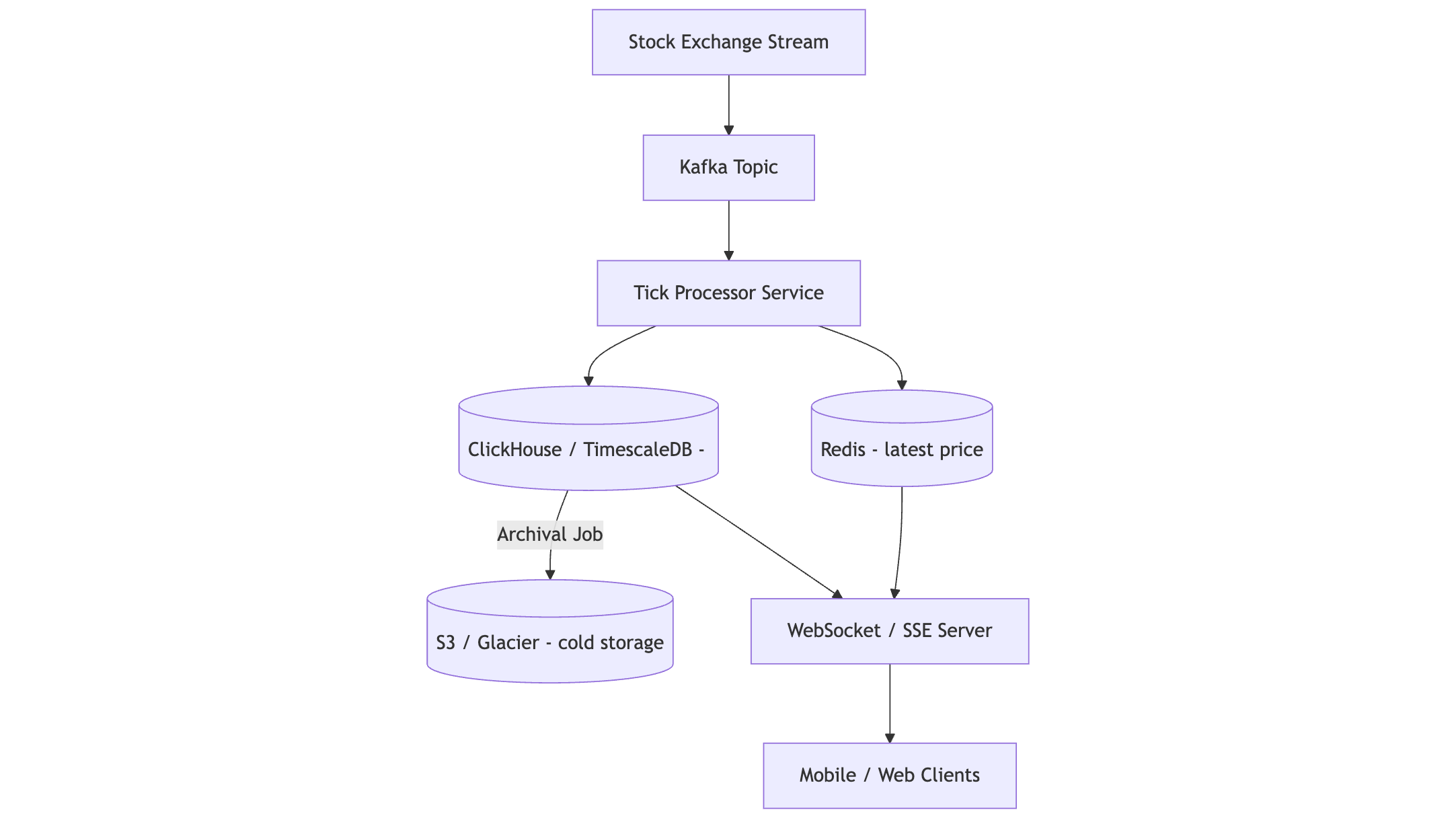
8. How Clients Receive Updates
- Option A — WebSockets
- Persistent connection
- Bidirectional
Ideal for frequent updates and mobile networks
-
Option B — SSE
- Unidirectional
- Auto-reconnect
Works well for dashboards
Both work, but WebSockets handle real-time stock prices better.
9. Scaling the System
Horizontal Scaling Made Easy
- Multiple Kafka consumers
- Multiple WebSocket server instances
- Redis used as central cache
- ClickHouse cluster (2–8 nodes)
- S3 for infinite retention
- Load Balancing WebSockets
- Enable sticky sessions so each client session stays on the same node.
10. Summary
- ✔ Real-time delivery → WebSockets
- ✔ Latest prices → Redis
- ✔ Warm storage → ClickHouse / TimescaleDB
- ✔ Cold infinite storage → S3 + Glacier
- ✔ Ingestion → Kafka
- ✔ Cleanup → Retention policies + archival jobs
This architecture:
- Scales Horizontally
- Cost Efficient
- Handles Infinite Data
- Performs well at real-time speed
- Matches real-world stock market platforms